Refining Pre-Trained Motion Models
Xinglong Sun Adam W. Harley Leonidas J. Guibas
Abstract
Given the difficulty of manually annotating motion in video, the current best motion estimation methods are trained with synthetic data, and therefore struggle somewhat due to a train/test gap. Self-supervised methods hold the promise of training directly on real video, but typically perform worse. These include methods trained with warp error (i.e., color constancy) combined with smoothness terms, and methods that encourage cycle-consistency in the estimates (i.e., tracking backwards should yield the opposite trajectory as tracking forwards). In this work, we take on the challenge of improving state-of-the-art supervised models with self-supervised training. We find that when the initialization is supervised weights, most existing self-supervision techniques actually make performance worse instead of better, which suggests that the benefit of seeing the new data is overshadowed by the noise in the training signal. Focusing on obtaining a "clean" training signal from real-world unlabelled video, we propose to separate label-making and training into two distinct stages. In the first stage, we use the pre-trained model to estimate motion in a video, and then select the subset of motion estimates which we can verify with cycle-consistency. This produces a sparse but accurate pseudo-labelling of the video. In the second stage, we fine-tune the model to reproduce these outputs, while also applying augmentations on the input. We complement this boot-strapping method with simple techniques that densify and re-balance the pseudo-labels, ensuring that we do not merely train on "easy" tracks. We show that our method yields reliable gains over fully-supervised methods in real videos, for both short-term (flow-based) and long-range (multi-frame) pixel tracking.
Method Overview
Step 1. Generate Motion Estimates
We first run the pretrained motion model on a unlabeled video to generate some motion estimates.
Step 2. Filter Estimates to Obtain Pseudo Labels
Then we design a cycle-consistency based filter to filter those estimates down to "good" and "clean" trajectories. Specifically, cycle consistency assumes that if for a good track, if we track forwards in time, then start at the endpoint and track backwards in time, we should end up at the original startpoint.
Step 3. Finetuning the Pretrained Model
In the next stage, we perform some augmentations on those good estimates, and finetune the same pretrained model to reproduce those estimations.
Results
Please see the paper for detailed quantitative results and analysis. Here, we show some visualizations of the performance.
Optical Flow
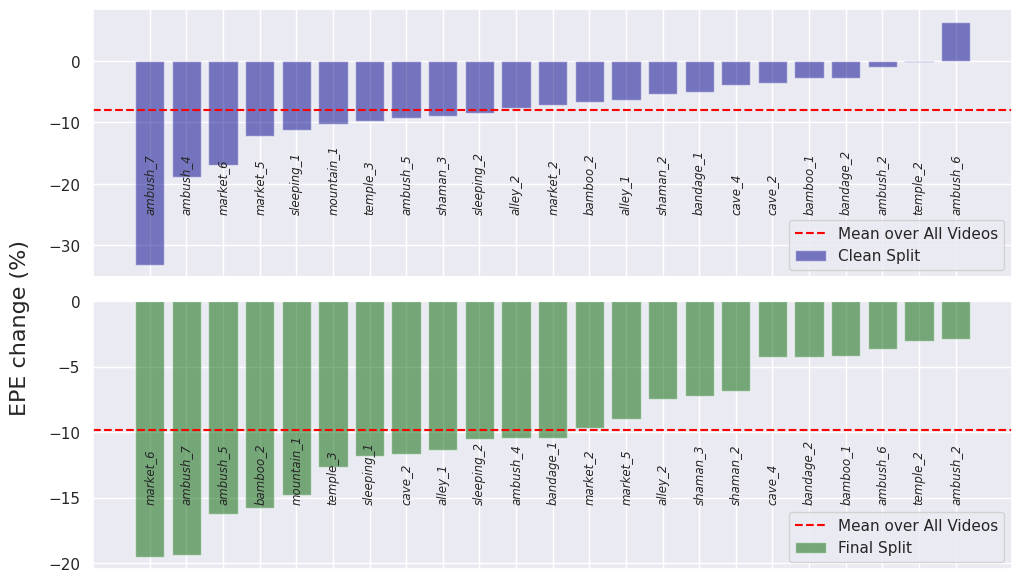
Percent change in EPE after our refinement for each video in the MPI Sintel dataset compared with the pretrained RAFT model. Negative value denotes improvement (i.e., error decreasing)
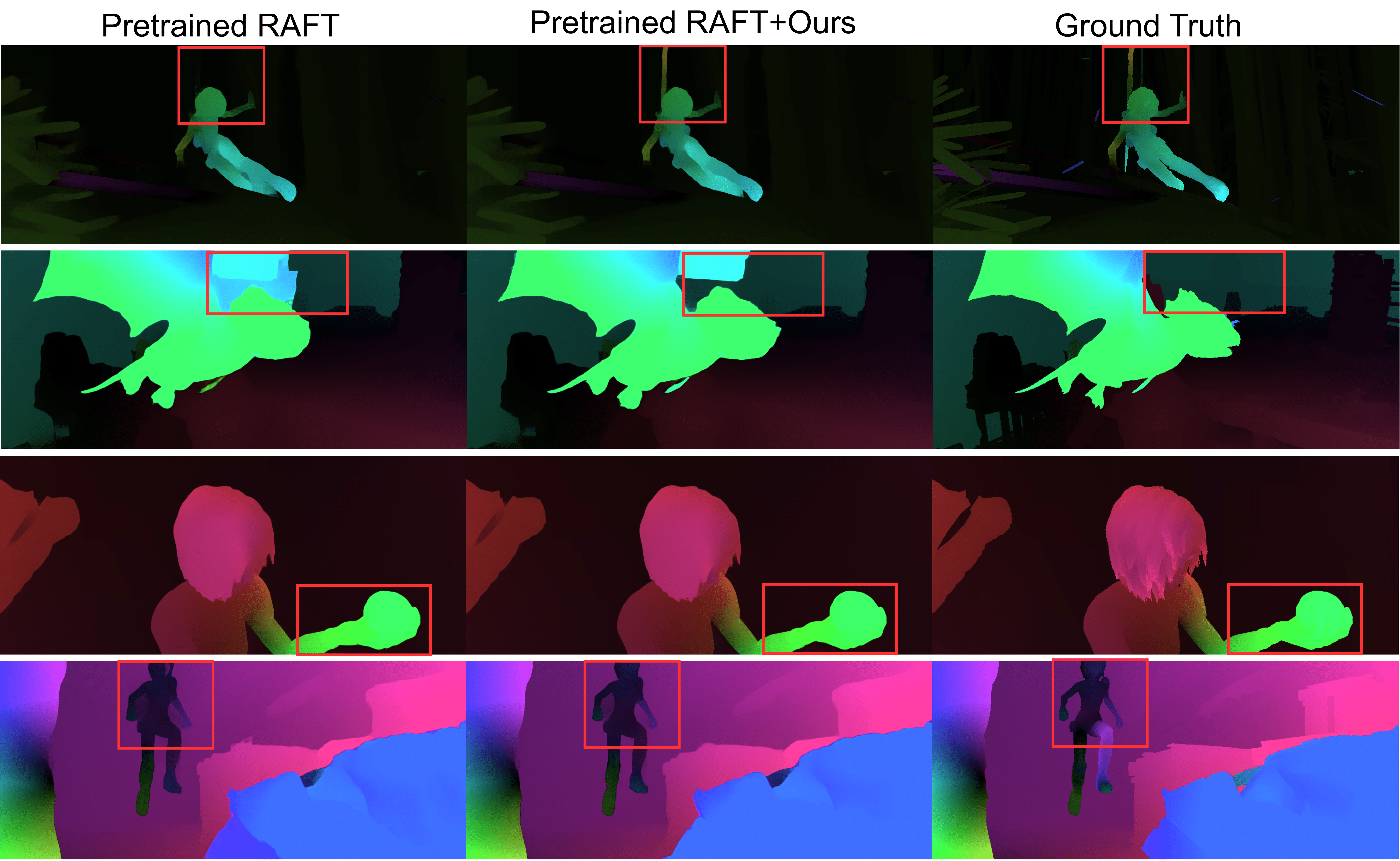


Our approach refines the flows by completing missing objects and cleaning noisy tracks.
Multi-frame Tracking
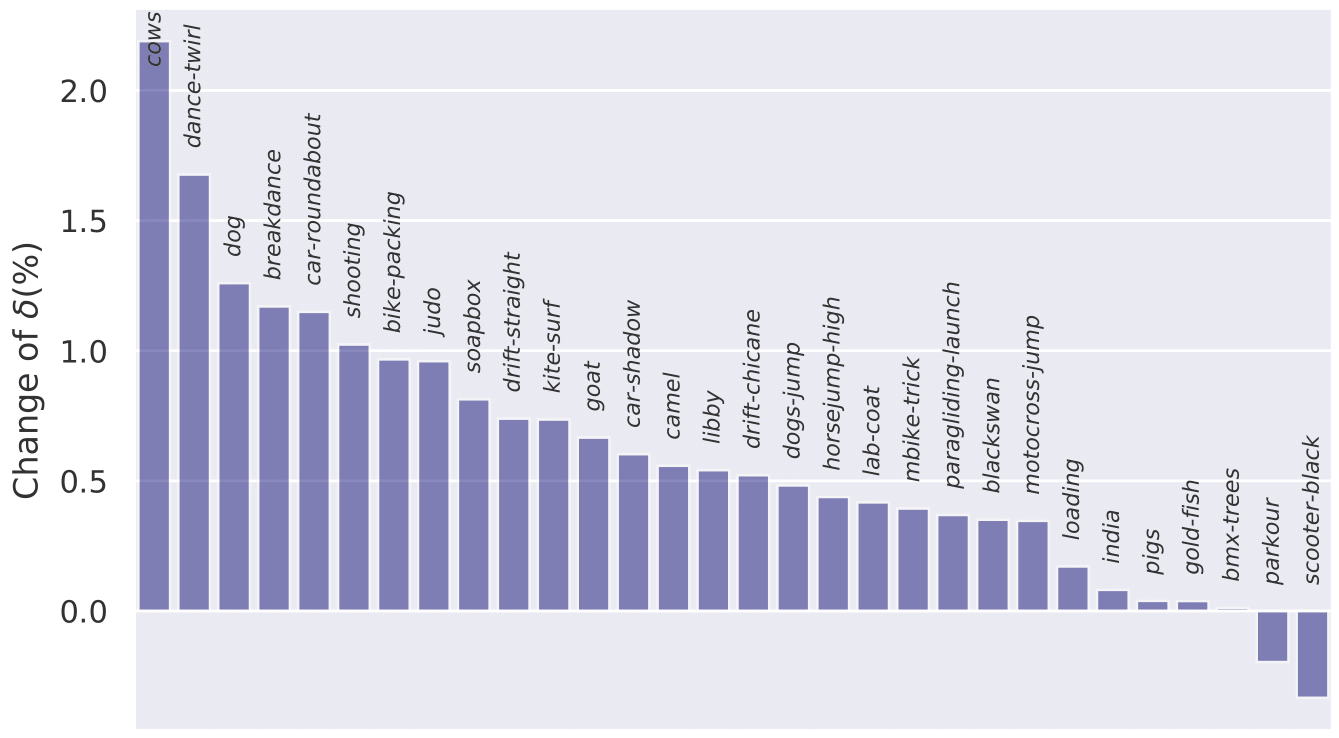
Performance change in δ after our refinement for each of the video in the TapVid-DAVIS dataset compared with the baseline pretrained PIPs model. Positive value denotes improvement (i.e., accuracy increasing)
Tracking a point on the background, original tracker is stuck on the moving car whereas our refinement fixes the error.
Tracking a point on the dancer's leg, original tracker loses the target in the middle whereas our refinement helps to keep the trajectory to the end.
Tracking a point on the dog, original tracker is stuck on the standing person whereas our refinment corrects this mistake.
Paper

Bibtex
@inproceedings{sun2024refining,
author = {Xinglong Sun and Adam W. Harley and Leonidas J. Guibas},
title = {Refining Pre-Trained Motion Models},
year = {2024},
eprint = {2401.00850},
archivePrefix = {arXiv},
}